
In a Data Warehousing platform, data is classified into two categories; as follows,
Hot Data
(Frequently accessed): data which needs to be live and immediately accessible to the user is Hot data. These data will be stored in the Data Warehouse and distributed to the Data Marts at the same time.
Cold Data
(Infrequently accessed): data which are required to be archived and accessed on a more infrequent basis (for example, during annual audits) are classified as Cold data. These data will only be stored in the Data Warehouse layer, further back.
Below is a list of a few approaches that we could consider while defining DW storage design.
Approach 1
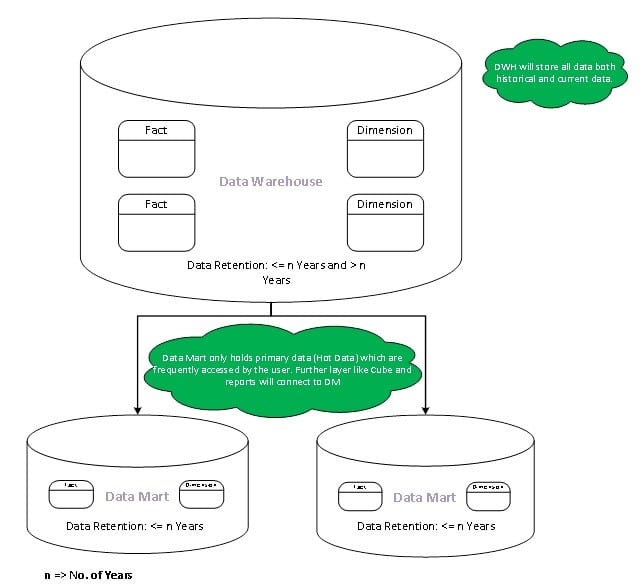
Overview
All Data are extracted from staging and loaded into the Data Warehouse. Delta data which are loaded into the Data Warehouse will then be mirrored to subject-specific Data Marts. Data Marts provide round-the-clock availability to Analysis (Cube) and Presentation (Reports) layers with primary/hot data. This avoids additional overhead on the Data Warehouse which will continue to grow in volume.
Entities
Fact
Fact tables in the Data Warehouse store values, including historical data back to the oldest point of time. Incremental data which are defined as primary/hot data will be pushed to the Data Marts. The fact tables in the Data Marts will be accessed by Analysis (Cube) and Report layers as they store frequently accessed data.
Distributing frequently accessed data to the Data Marts ensures rapid data retrieval and processing time.
Dimension
Dimension tables store descriptive attributes, related to values in the Fact tables. Current and changed members in dimension tables will be stored in the Data Warehouse. Only the valid/active members will roll into Data Marts, unless there is an exceptional requirement from users to include all the members including changed members (Historic members).
Advantages
- Data stored in two different database layers optimises query execution and processing time.
- Frequently accessed data can be analysed more quickly, with less performance issues.
- Improved data excellence in terms of accessibility, as only essential data will be brought into Data Marts.
Disadvantages
- Additional ETL jobs are required to integrate data into Data Marts as well as the Data Warehouse.
- A separate on-demand tool may be required for querying cold-data in the Data Warehouse.
Approach 2
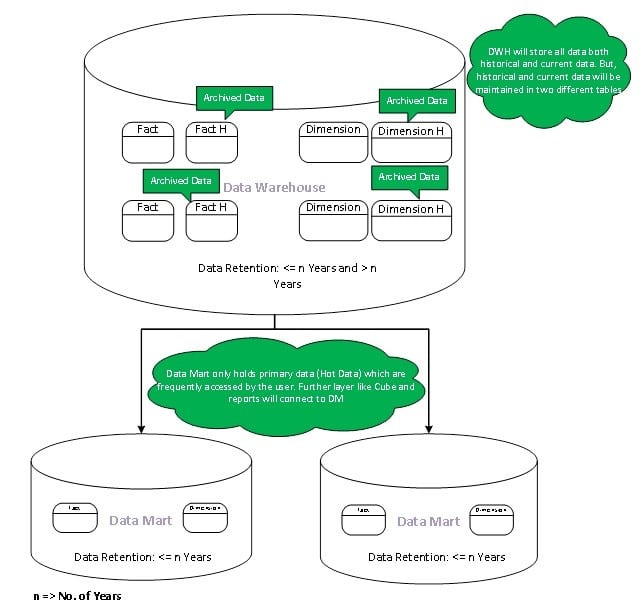
Overview
All Data are extracted from staging and loaded into the Data Warehouse. In the Data Warehouse, two versions of the data will be stored. The first set of tables will hold frequently accessed data. The second set will hold historical data. The tables that hold recent data will be replicated to the Data Mart.
Entities
Fact
Fact tables in the Data Warehouse store values, including historical data back to the oldest point of time.
Incremental data which are defined as primary/hot data will be stored separately in the Data Warehouse and then pushed on into the Data Marts. Data defined as historical/cold data will be stored separately in the Data Warehouse. The fact tables in the Data Marts will be accessed by Analysis (Cube) and Report layers as it stores frequently accessed data.
Distributing frequently accessed and historic data in a Data Warehouse optimises the data transform time, as the data will be separated by the Data Warehouse layer, rather than in the process of loading into Data Marts.
Dimension
Dimension tables store descriptive attributes, related to values in the Fact tables. Current and changed members in dimension tables will be stored in separate sets of tables in the Data Warehouse. Slowly-changing members will be moved to history dimension tables. Valid/Active members will be held in active dimension tables and will be pushed into Data Marts, unless there are exceptional requirements from users to include all the members.
Advantages
- Data maintained as two different tables (Current/ History) in the Data Warehouse improves data extraction and transforming to the Data Marts.
- Frequently accessed data can be analysed more quickly, with less performance issues.
- Improved data excellence in terms of accessibility, as only essential data will be brought into Data Marts.
Disadvantages
- Larger database size in the Data Warehouse can increase the database maintenance overhead.
- A separate on-demand tool may be required for querying cold-data in the Data Warehouse.
- Additional jobs needed to update/integrate two tables.
Approach 3
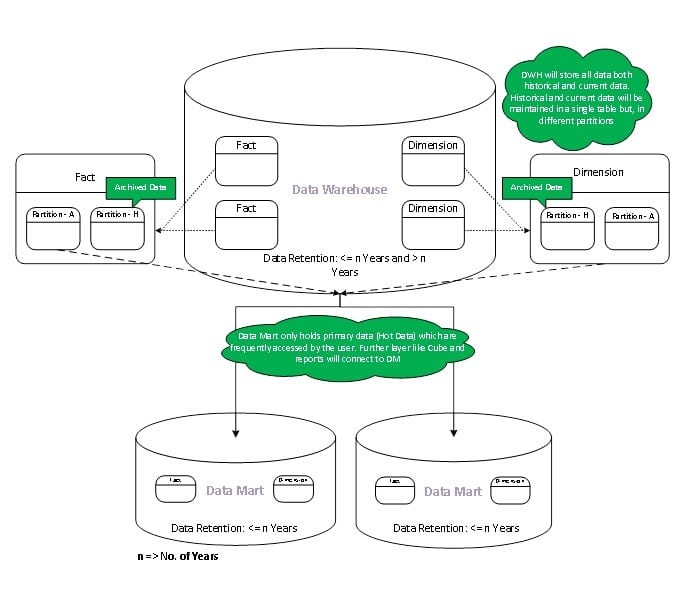
Overview
All Data are extracted from staging and loaded into the Data Warehouse. In the Data Warehouse, data will be maintained in a single table, but data will be distributed into two different partitions. The primary partition will store hot data which is frequently used and the secondary will store historical data. The Data Marts will use the primary partition as their source. Data will be stored in a single table similar to the approach-1 but logically divided using partitions which provide faster access of data.
Entities
Fact
Fact tables in the Data Warehouse store values, including historical data back to the oldest point of time.
The data will be divided into two different partitions. Fact will be distributed into two different partitions as one keeps history data and other one stores current and frequently accessed data. Frequently accessed/incremental data which are identified as primary/hot data will be transmitted to the Data Marts using the primary partition. The fact tables in the Data Marts will be accessed by Analysis (Cube) and Report layers as it stores frequently accessed data.
Logically allocating frequently accessed and historic data in a Data Warehouse into separate partitions optimises querying time when loading facts into the Data Marts.
Dimension
Dimension tables store descriptive attributes, related to values in the Fact tables.
Current and changed members in dimension tables will be stored in the Data Warehouse. Current and historical members will be logically divided using partitions. Valid/Active members will roll into Data Marts unless there are exceptional requirements from users to include all the members including changed members.
Advantages
- Data stored in a single table but logically split into two different partitions (Current/History) in the Data Warehouse improves data extraction and transforming to the Data Marts.
- Frequently accessed data can be analysed more quickly, with less performance issues.
- Improved data excellence in terms of accessibility, as only essential data will be brought into Data Marts.
Disadvantages
- Overhead in database maintenance since Partitioning is involved.
- A separate on-demand tool may be required for querying cold-data in the Data Warehouse.
- Additional jobs needed to update/integrate two tables.